umcconnellJust my personal websiteumcconnell2024-08-25T00:00:00Zhttps://www.umcconnell.net/Stars and Bars2024-08-25T00:00:00Zhttps://www.umcconnell.net/posts/2024-08-25-stars-bars/How many ways are there to distribute n undistinguishable items into k bins?
Consider the following illustration for the situation where we distribute 7
items (stars) into 4 bins (intervals between bars) indicated by separators:
⋆⋆|⋆⋆||⋆⋆⋆
We see that the problem is equivalent to choosing k−1 out of the overall
n+k−1 positions for separators (bars) before placing n items (stars) in
the remaining slots.
This leads to the following conclusion:
Lemma (Stars and Bars)
Let n,k∈N with k≥1. The number of ways to place n
undistinguishable items into k bins is given by
(k−1n+k−1)(1)
Equivalently, eq. (1) gives the number of non-negative integer solutions to the
following equation where xi∈N for 1≤i≤k:
x1+⋯+xk=n
Example
Let’s consider the following example problem, where n,k∈N with
n≥k:
How many different ways are there to select exactly k elements from
{1,…,n} such that the sum of these elements is at most n?
This problem can be reformulated as follows:
How many solutions does the inequality x1+⋯+xk≤n permit for
natural numbers xi≥1?
We can rewrite the inequality to use non-negative integer variables yi by
adding 1 to every variable, as well as adding a dummy term yk+1
representing the (non-negative) difference between the right- and left-hand side
to obtain an equality:
(y1+1)⟺y1+⋯+(yk+1)+⋯+yk+yk+1≤n=n−k
By the Stars and Bars lemma (1), this problem has
((k+1)−1(n−k)+(k+1)−1)=(kn)
solutions.
]]>Podcast Synchronization Over the Cloud2024-08-23T00:00:00Zhttps://www.umcconnell.net/posts/2024-08-23-opodsync/As a regular and avid podcast listener, I was looking for a solution to
synchronize my subscriptions and episode status across several devices. On
mobile, I use the excellent Antenna Pod
app, while on desktop I rely on gPodder.
Since the open-source synchronization server gPodder.net
frequently encounters status 500 errors, I decided to set up my own
synchronization server using the lightweight, gPodder-compatible
opodsync.
In this guide, I will describe how to set up opodsync on Google Cloud. Before
starting, ensure you have a Google Cloud account and a domain name through which
the synchronization server will be accessible.
Server
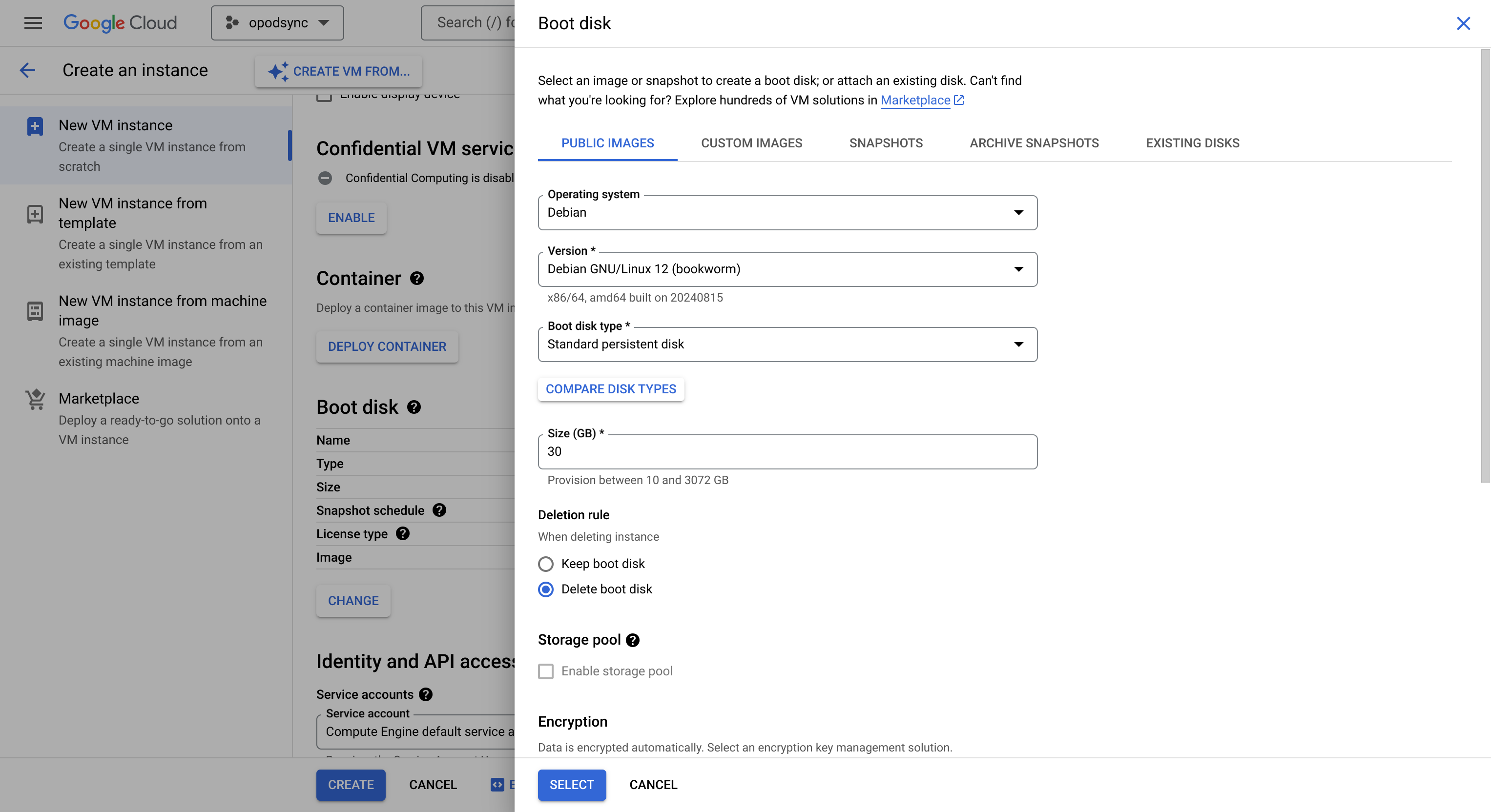
To get started, create a new virtual machine (VM) from the cloud dashboard. This
option is also accessible through the resources tab or in the sidebar under
“Compute Engine”. I used the small e2-micro instance which is sufficient for
this task, and also has the advantage of being part of the free tier. As of this
writing, the following configuration options are part of the free tier:
Note that a monthly estimate of costs (around 7 USD for the above configuration)
will be shown, even if your selection is covered by the free tier.
Once the VM is created, connect to it through SSH to install the synchronization
server. The easiest way to connect is through the web interface, which opens a
terminal directly in your browser. To do this, go to the VM instance overview
(found under “Compute Engine” in the sidebar) and click “SSH”.
As a first step, install the Apache server:
BASH
sudoapt update &&sudoapt-yinstall apache2
Check that Apache is running:
BASH
sudo systemctl status apache2
At this point you can check that the server is reachable online. In the VM
instances overview, copy the external IP. You should see the Apache default page
when navigating to http://YOUR.EXTERNAL.IP.ADDRESS. Important: Make sure
you are not trying to connect through HTTPS (this may be the default when
clicking on the link), as HTTPS will be set up later.
Opodsync
Next, install php7.4 and a few other required dependencies:
You should now be able to access the landing page, although redirects to the
login and register pages won’t work until the custom domain is set up.
DNS
Before setting up HTTPS, make sure you can access the site through the chosen
domain name. Add an A record pointing to the public IP address of your VM.
This should match the ServerName in the Apache server configuration.
Once everything is set up, you should be able to access the server through your
domain name and also access the login/register page.
TLS
Setting up HTTPS is straightforward using
Let’s Encrypt. Just install certbot and follow the
instructions. Cerbot will automatically configure the Apache server to properly
redirect to HTTPS:
You should now be able to register your first user through the web interface. By
default, opodsync will block further user registration, but this can be changed
in the settings.
Podcast apps
The last step is to set up your podcast apps. In AntennaPod, navigate to
Settings > Synchronization and use the custom domain name and your user
credentials to log in. For gPodder, this option is available through
Preferences > gpodder.net. Note that for gPodder you must use the
“gPodder secret username” that is displayed when logging in to opodsync.
Happy synchronizing!
]]>Dirac's theorem on Hamiltonian Graphs2024-07-31T00:00:00Zhttps://www.umcconnell.net/posts/2024-07-31-dirac-theorem-hamiltonian/Overview & Background
Continuing the theme of last post, we will look at a classic result in graph
theory, namely Dirac’s theorem on Hamiltonian cycles. This result was first published by
Gabriel A. Dirac in 1952 [1], with later refinements
by Ore, as well as Bondy and Chvátal. Three proofs of the theorem will be presented: the original proof from Dirac’s paper,
an induction proof, and a short and direct proof. We will also consider the tightness of the bound as well as a
generalization by Ore.
As a little historical sidenote before diving into the mathematics, Gabriel Dirac was the son of Margit Wigner,
the sister of famous physicist Eugene Wigner. After a first marriage, from which Gabriel was born, Margit later
remarried Eugene Wigner’s friend Paul Dirac, another equally famous physicist and one of the founders of
Quantum Mechanics. Subsequently, Gabriel chose to take on the name Dirac. More interesting biographical details
can be found in the essay about Paul Dirac on MacTutor.
Although the following definitions are standard in graph theory, it is useful to specify them at the outset
as these terms are often used rather loosely. A path is a sequence of non-repeating vertices and edges, where
subsequent vertices are connected by an edge in the graph. Usually we distinguish between open and closed paths,
where as the name implies, an open path just has different start and end vertices, while a closed path starts
and ends with the same vertex. A closed path is also called a cycle. The length of a cycle is the number of distinct
vertices on the cycle (the equal start- and end-vertex is not counted twice). As always, I will try to stick to
common graph theoretical notation and conventions, but for the sake of both readability and completeness an overview
of notation is given at the end of the post.
A Hamiltonian cycle is a cycle through a graph that visits every vertex exactly once. This concept might sound similar
to Euler tours, that are historically at the origin of graph theory. An Euler tour is a cycle that visits every edge
exactly once, while repeated vertices are allowed. However, in contrast to Euler tours which can be found in a graph in
linear time O(∣V∣+∣E∣), finding and even checking whether a graph contains a Hamiltonian cycle is in general
NP-complete, i.e. no known polynomial time exists for this problem. Finding a Hamiltonian cycle and the related
optimization problem of finding a lowest weight Hamiltonian cycle (known as the
travelling salesperson problem) has many applications
from computer graphics and circuit design to cargo routing and bioinformatics.
We will consider Dirac’s theorem, which is a sufficient condition for graphs to contain a Hamiltonian cycle:
Theorem (Dirac, 1952)
Let G=(V,E) be a graph with ∣V∣≥3 and minimum degree δ(G)≥2∣V∣ on every vertex.
Then G contains a Hamiltonian cycle.
Equivalently, every graph with minimum degree δ(G)=d and at most ∣V∣≤2d vertices contains a Hamiltonian
cycle.
Notice that the conditions of this theorem are not necessary for a Hamiltonian cycle, as for example a cycle graph Cn
on n vertices violates the degree condition but clearly contains a Hamiltonian cycle.
Connectedness
As a warm-up we’ll start by showing that such a “Dirac-graph” is connected, ie. G contains a path between
any two vertices. In his original paper, Dirac writes in the theorem formulation that the graph must be
connected, but as we will see now, this is not strictly necessary. Every graph that obeys the degree condition
must also be connected.
In fact, we will see that any two vertices are connected by a path of length at most two, where the length of a
path is defined as the number of edges along that path. Consider two arbitrary vertices u,v∈V. Without loss
of generality we may assume that {u,v}∈E, as otherwise we would be done. We therefore know that the
neighborhoods N(u),N(v) of u and v respectively do not contain the other vertex. But
by the assumption on the minimum degree in G we also know that N(u)≥2∣V∣ as well as
N(v)≥2∣V∣. We can now apply the pigeonhole principle to conclude that u and v must
have a neighbor in common, and are therefore connected by a path of length 2: Both neighborhoods do not contain
u and v by the previous observation, so we are trying to distribute two neighborhoods of size at least
2∣V∣ onto ∣V∣−2 vertices. The two must necessarily intersect.
Alternatively, this same fact can be seen by applying the inclusion-exclusion principle:
We can already start seeing, why this theorem is tight. Relaxing the degree constraint on the vertices would
for example allow a graph G′ that is the disjoint union of two complete subgaphs on half of the vertices:
for X=K2∣V∣ and Y=K2∣V∣ (ignoring odd ∣V∣ for simplicity here) we could
construct G′=X⊎Y with a minimum degree of δ(G′)=2∣V∣−1 for every vertex.
This graph clearly does not contain a Hamiltionian cycle
In the following three proofs, we will always assume that G is a graph as described in the theorem,
i.e. G=(V,E) with δ(G)≥2∣V∣.
Original proof
Dirac’s original proof [1:1] is a little more convoluted, but we will consider it for completeness.
It contains a few unnecessary convolutions, such as two nested proofs by contradiction, that hide
the essence of the argument. Feel free to skip to the next section if you are not
interested in the exact technical details of the original paper.
We will start by showing the following lemma:
Lemma 1
Let G=(V,E) be a graph as defined in Dirac’s theorem. Then G contains a cycle of length at least δ(G)+1.
A longest path P=v1,…,vk in G must contain at least 2∣V∣+1 vertices, because v1 has
at least δ(G)=2∣V∣ neighbors. Otherwise v1 would have a neighbor outside of P that we could
use to extend P. Therefore, all neighbors of v1 must lie on P, which immediately yields a cycle of length at
least δ(G)+1: v1,…,vi,v1 where i≥δ(G)+1 is the highest index of neighbors of v1
along P.
Now assume for sake of contradiction that the theorem is false, i.e. there exists a graph G=(V,E) satisfying
∣V∣≥3 and δ(G)≥2∣V∣ on every vertex that does not contain a Hamiltonian cycle.
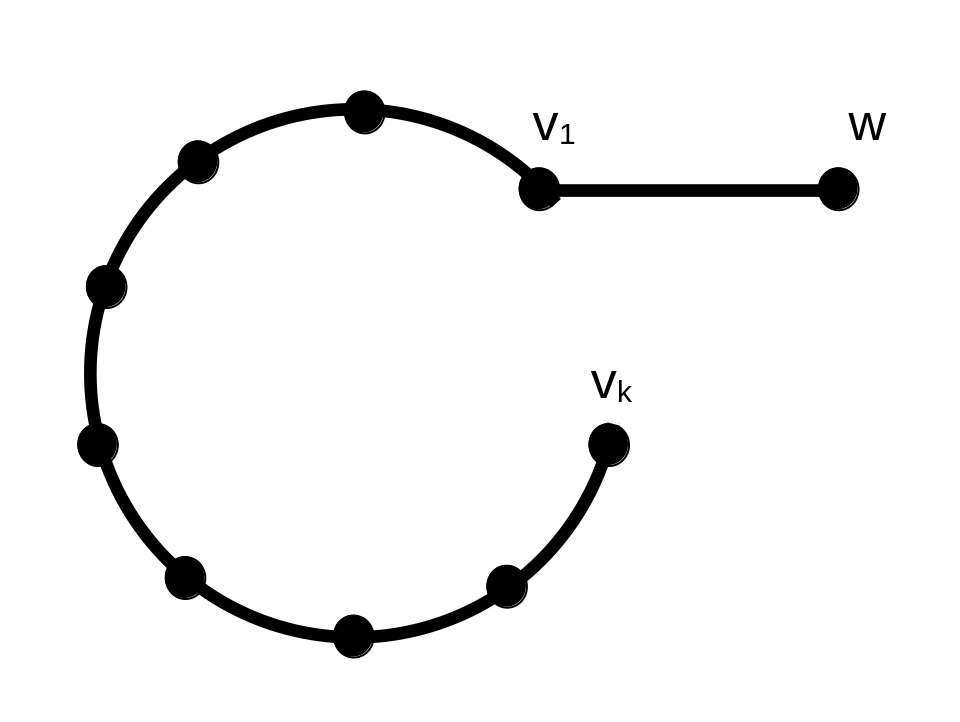
Let C=v1,…,vk be the longest cycle in G. By our assumption, C has length at most
∣V∣−1. From the lemma it also follows that the cycle C must have length at least 2∣V∣+1.
As G is connected, some node in C, let’s assume without loss of generality that it is vk, must be connected to some
node vk+1 in V∖C. We will now consider the longest path P′=vk,vk+1,…,vk+l that
is entirely contained in V∖C except for vk. By the same observation as in the proof for the lemma,
vk+l can only be connected to v1,…,vk,…,vk+l−1.
Under these assumptions made for sake of contradiction, the following lemma holds:
Lemma 2
Under the assumption that Dirac’s theorem is false, it holds that l≥2∣V∣.
We will show this lemma again by contradiction. If l≤2∣V∣−1<2∣V∣, then vk+l
must be connected to at least δ(G)−l≥2∣V∣−l≥1 vertices in
v1,…,vk−1, excluding vertices vk,…,vk+l−1 in P′. So vk+l must be connected to
another vertex vi∈C with vi=vk. We can estable the following two inequalities on i:
i≥l+1: We can form a new cycle C′=vk+l,vi,…,vk,…,vk+l of length k+l−i+1.
Because C is the longest cycle in G, we obtain k+l−i+1≤k⟺i≥l+1
i≤k−l−1: We could also form a new cycle C′′=v1,…,vi,vk+l,…,vk,v1 of length
i+l+1. Just as before we obtain i+l+1≤k⟺i≤k−l−1.
By the two inequalities, we conclude that vk+l is connected to at least 2∣V∣−l≥1 vertices
in I=vl+1,…,vk−l−1. Notice that there are ∣I∣=k−2l−1 such vertices.
However, it is also not possible that vk+l is joined to two neighboring vertices vi and vi+1 in I, as
this would contradict the maximality of the original cycle C. Otherwise C could have been extended to
v1,…,vi,vk+l,vi+1,…,vk,v1 of length k+1. By this observation, there must therefore be at
least 2(2∣V∣−l)−1 such vertices in I in order to intersperse every neighboring vertex of vk+l with
a non-neighbor. Putting all these inequalities together, we finally obtain:
∣I∣=k−2l−1>2(2∣V∣−l)−1⟺k≥∣V∣
But this cannot be, as we assumed that C is not a Hamiltonian cycle. This proves lemma 2.
Proving Dirac’s theorem is now fairly straightforward, by completing the outer proof by contradiction. As we have
already observed previously, C has length at least 2∣V∣+1 by lemma 1. Because G is composed of at
least C and P′, both distinct from each other by construction, we can apply our bound on ∣P′∣ from lemma 2:
∣V∣≥∣C∣+∣P′∣≥2∣V∣+1+2∣V∣≥∣V∣+1
This contradiction concludes the proof.
Double induction
As a first proof of Dirac’s theorem, we will consider a proof by induction. This uses the
so-called rotation-extension technique by Pósa[2]. Personally, I find this proof to be the
most elegant of the three, especially because of the neat double induction that is used. The
general structure of the proof consists of two parts:
A k-cycle implies the existence of a k+1-path, as G is connected
A k-path implies the existence of a k+1-path or a k cycle.
By induction G thus has an ∣V∣-cycle, i.e. a Hamiltonian cycle.
Recall that we already saw previously, that G is connected. This fact will be
needed in the induction proof.
Induction I
For k<∣V∣, a k-cycle implies the existence of a k+1-path.
Let C=v1,…,vk,v1 be such a cycle in G. Because G is connected, there
exists an edge e=(w,vi) from V∖{v1,…,vk} to C, where w is a
vertex outside of the cycle. Without loss of generality we may assume that vi=v1.
We have found a k+1-path w→v1→⋯→vk.
Induction II
A k-path implies the existence of a k+1-path or a k-cycle.
Let P=v1,…,vk be such a path in G.
CaseN(v1)⊆{v2,…,vk}: P can be
extended to a k+1-path w→v1→⋯→vk, where w
is a neighbor of v1 not in P.
CaseN(vk)⊆{v1,…,vk−1}: same as above
CaseN(v1)⊆{v2,…,vk} and
N(vk)⊆{v1,…,vk−1}:
Let the extended neighborhood
N+(vk):={vi+1∣vi∈N(vk)} be the set of successors of neighbors on the path. Note that by assumption, all neighbors (and their successors) of vk lie on P. By applying the inclusion-exclusion principle again we obtain:
This implies that there exists a vi in N(v1)∩N+(vk).
We have found a k-cycle v1→⋯→vi→vk→⋯→vi+1→v1
Conclusion
By combining both parts of the induction, we conclude that there must exist an n-path, and by
Induction II, an ∣V∣-cycle, i.e. a Hamiltonian cycle in G, as G cannot contain an ∣V∣+1 path
(paths have distinct vertices).
Direct proof
This is the shortest of the three proofs that will be presented, and is conceptually very similar to the
induction proof. It can be found in standard textbooks on graph theory, such as the
one by Diestel [3]. We will first inspect a longest path in G and show that it can be extended
to a cycle. We will then prove that this cycle must actually be a Hamiltonian cycle.
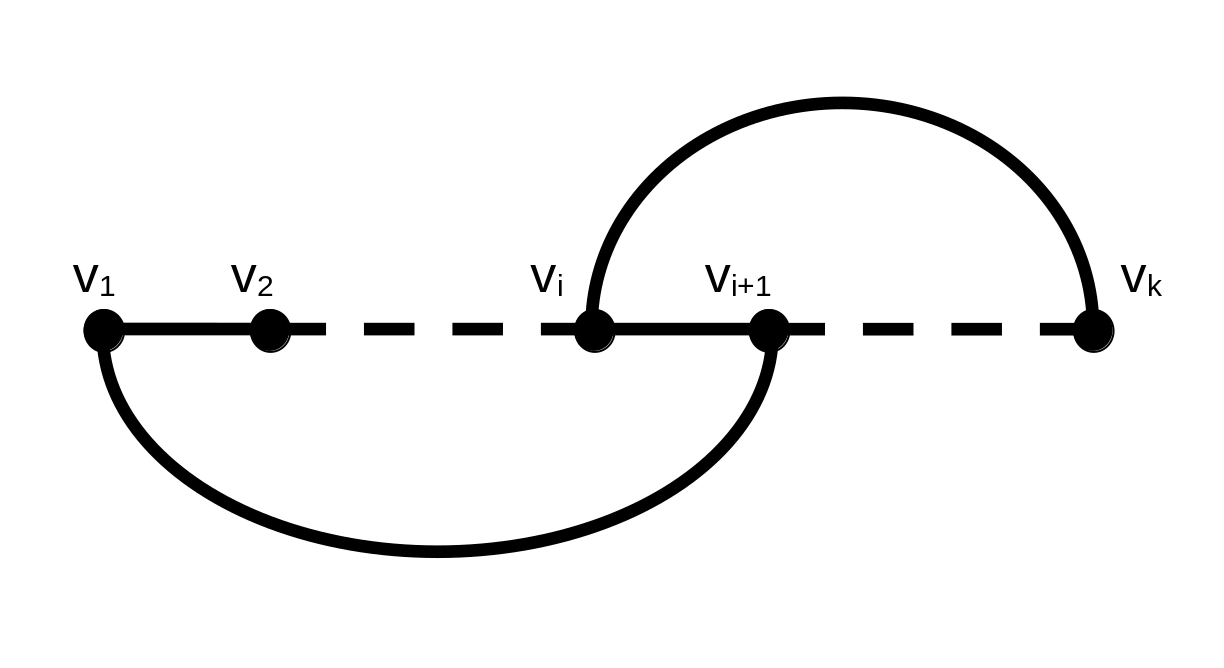
Consider a longest path P=v1,…,vk in G. All edges of v1 and vk must end in P,
as otherwise we could extend P, contradicting the fact that P is a longest path. By the same argument
as in case 3 of Induction II, we can find an edge vivi+1 in the path,
where also both {v1,vi+1}∈E and {vi,vk}∈E. We can then turn P into a cycle
C=v1,vi+1,…,vk,vi,…,v1.
Finally, assume for sake of contradiction that C is not a Hamiltonian cycle. Then there must exist
at least one vertex in V∖C. However, as G is connected, there must also exist an edge
{u,vi} for u∈V∖C and vi∈C, where we can assume vi=v1 without loss
of generality. This is a contradiction to our initial assumption that P is a longest path in
G, as u,v1,…,vk would form a longer path.
Tightness
We will use the second equivalent formulation of Dirac’s theorem, that bounds the number of vertices as a function of the minimum degree
d=δ(G). This will make the tightness result simpler to formulate.
Let us first make a general observation about bipartite graphs that will come in handy in a moment.
Recall that bipartite graphs are graphs that can be seperated into a disjoint union of two sets X
and Y with edges only between these two sets.
Lemma
Bipartite graphs cannot contain cycles of odd length (where length refers to the number
of edges along the path).
Equivalently, a cycle v1,…,vn,v1 with n odd cannot exist.
First, notice that any path in a bipartite graph consists of alternating vertices from both sets,
because a vertex is only connected to vertices from the other set. Therefore
any path of odd length must have start and end vertices in different sets, which cannot
possibly form a cycle where start and end vertex are the same.
The construction exhibiting tightness is a simple bipartite construction. We will construct a graph with 2d+1
vertices and show that this graph does not contain a Hamiltonian cycle. Consider vertices v1,…,v2d+1
and let “even” vertices be those with an even index while “odd” vertices refer to those with an odd index.
We connect every even vertex only to all other odd vertices and vice-versa. This construction can also be compactly
written as Kd+1,d using standard graph theory notation.
There are d+1 odd vertices and d even vertices, i.e. we are “barely” violating the degree conditions of the initial
theorem. Even vertices have degree deven=⌈22d+1⌉=d+1 while odd vertices have degree
dodd=⌊22d+1⌋=d.
Notice however, that this graph is clearly bipartite: Color say all even vertices red and all odd vertices blue,
then by construction vertices of the same parity are not connected. But bipartite graphs cannot contain odd-length
cycles as seen in the lemma above, which shows that this construction cannot contain a Hamiltonian cycle.
Ore’s theorem
Finally, let’s consider a generalization of Dirac’s theorem. The Norwegian mathematician
Øystein Ore published
the following theorem in a one-page paper in 1960[4]:
Theorem (Ore, 1952)
Let G=(V,E) be a graph with ∣V∣≥3. If for every pair of non-adjacent vertices u and v with
{u,v}∈E we have degG(u)+degG(v)≥∣V∣, then G contains a Hamiltonian cycle.
This observation essentially follows from the proofs presented above. In the previous proofs, we repeatedly
made use of the fact that two disconnected vertices can be connected through two adjacent neighbors. The
condition that degG(u)+degG(v)≥∣V∣ for two non-adjacent vertices ensures exactly this: The
neighborhoods N(u) and N(v) must intersect.
We will prove this by contrapositive:
Assume for sake of contradiction that Ore’s theorem is false, i.e. there exists a graph with ∣V∣≥3
satisfying degG(u)+degG(v)≥∣V∣ for {x,y}∈E that does not contain a Hamiltonian cycle.
Let G be the the one with a maximum number of edges among those. Notice that G must contain a non-edge
{x,y}∈E, as the complete graph K∣V∣ clearly contains a Hamiltonian cycle. Therefore we know
the statement does not just hold vacuously.
Now, adding {x,y} to G must necessarily close a Hamiltonian cycle x=v1,…,vn=y by our choice of G.
Here we can however again apply case 3 of the induction proof (with the knowledge that
∣N(x)∣+∣N+(y)∣≥∣V∣) to conclude that {x,y} was not
necessary to close the Hamiltonian cycle. There must be an edge vivi+1 in the path,
where also both {x,vi+1}∈EG and {vi,y}∈EG. We obtain a cycle
C=x,vi+1,…,y,vi,…,x in G, a contradiction.
We will show that for a locally dense graph we can give a strong upper bound on the number of
independent sets of a certain size. This specific method for graphs is an instance of the
so-called container method, that allows to
give bounds on structures appearing in larger objects with specific local properties. More
specifically as applied to graph theory, this turns out to be quite helpful in proving lower
bounds in Ramsey theory.
The proof presented here follows the one presented in the survey paper by Samotij [1] using
methods originally presented in the paper by Winston and Kleitman [2]. Some elementary knowledge
of graph theory is helpful, such as the notion of independent sets and induced subgraphs, but I
try to be as explicit and clear as possible. I will try to stick to common graph theoretical
notation, but for the sake of both readability and completeness an overview of notation is given
at the end of the post.
Basic bounds
Let’s start with some basic bounds on the number of independent sets ∣I(G)∣ in a
graph G. Recall that an independent set is a set of vertices in which no two are connected by
an edge. If α(G) refers to the independence number, ie. the size of the largest independent
set in G, we can certainly say that
2α(G)≤∣I(G)∣
because every subset of the largest independent set is itself an independent set (recall that
2∣N∣ is the number of different subsets that can be formed from a set N).
Similarly, we can give an upper bound of
∣I(G)∣≤k=0∑α(G)(k∣V(G)∣)
as every independent set is a subset of size at most α(G) over the vertices of G.
Theorem Statement
We will now bound the number of independent sets of a certain size in a locally dense graph by
showing that every independent set is part of a small container. These containers are constructed
with the Kleitman-Winston algorithm. By counting these countainers, we can estimate the number of
independent sets. The tightness property of the containers then allows us to give useful bounds on
the number of independent sets.
Let us now turn to the actual theorem. For N,R,q∈N and β∈R with
β∈[0,1], let G be a graph on N vertices satisfying:
N≤Reβq(1)
In addition, we also require that G must be a β-locally dense graph. That is, for every
vertex subset A⊆V(G) of size at least R we have the following lower bound on the
number of edges in the induced subgraph G[A]:
eG(A)≥β(2∣A∣)(2)
Note that this corresponds to the situation where the subgraph spanned by A over G contains
at least a β-fraction of the edges of the corresponding complete graph over A, or in
other words, that the average degree of A is at least β(∣A∣−1).
Theorem
Given such a β-locally dense graph G satisfying (1) and (2), we can construct up to
(qN) small containers C1,…,Ci for 1≤i≤(qN) of size at
most R+q. Every independent set of size exactly q+k for k≤q belongs to a container
Ci.
For the number of independent sets in G of size exactly q+k we obtain:
∣I(G,q+k)∣≤(qN)(kR)(3)
Algorithm
Before describing the algorithm, let us fix a few technicalities. We need the notion of
max-degree ordering to ensure high-degree vertices are quickly removed from the graph and the
container quickly shrinks. For a vertex set A⊆V(G), the max-degree ordering
(v1,…,v∣A∣) is defined by the degree of vertices over the induced subgraph G[A]
in descending order, where potential ties are broken by a fixed but arbitrary total order over
V(G). In this case v1 has the highest degree, etc.
The Kleitman-Winston algorithm works by iteratively removing high-degree vertices as outlined
above:
Kleitman-Winston algorithm
Input: Independent set I∈I(G), integer q≤∣I∣
Output: selected vertices S, available vertices A
Procedure:
Set available vertices A=V(G), selected vertices S=∅
Iterate for i=1,…,q:
Let A=(v1,…,v∣A∣) be ordered by max-degree
Let ti be the first index in the ordering of A such that vti∈I
(i.e. first remaining vertex of I by max-degree ordering in induced subgraph G[A]).
Move vti from A to S
Remove higher-degree vertices Xi=(v1,…,vti−1) from A: A=A∖Xi
Remove vti and its neighborhood NA(vti) from A: A=A∖({vti}∪NA(vti))
Output S and A
The container of I is given by C:=S∪A. Notice that the tightness of the container is apparent in that fact
that S⊆I⊆C.
Proof
The algorithm maintains a few invariants, that help prove correctness: ∣A∣ decreases monotonically as we remove vertices in every iteration, while ∣S∣ increases monotonically.
Also notice that the previous observation S⊆I⊆(S∪A) holds at every
iteration of the algorithm.
It is clear that the algorithm always succeeds in constructing the set of selected vertices S
from q≤∣I∣ vertices of I. This is because the algorithm always selects the next highest
degree vertex vi of I occuring in the subgraph G[A] at every step, i.e. no vertex
vi∈I is ever removed from A and not added to S as a discarded higher-degree vertex.
In addition, the vertices of I form an independent set by assumption, and as such a vertex vi
is never removed as part of the neighborhood of another selected vertex.
Size of A
To conclude tightness of the containers, we must show that the final A returned from the
algorithm is sufficiently small. In fact, we will show that ∣A∣≤R. In the following, we
will denote by Ai the set of available vertices at the beginning of the i-th iteration of the
algortithm, and by Ai′=Ai∖Xi the set of available vertices after removing
higher-degree vertices but before remoing vti∈I.
First, note that by the Handshaking lemma
we obtain an expression for the average degree of vertices:
∣V∣1v∈V∑deg(v)=∣V∣2∣E∣(4)
Suppose for sake of contradiction ∣A∣>R for the final set of available vertices. Then it must
be that the vti∈S selected in every iteration must have been selected from a set of size
at least R, even after removal of other higher-degree vertices (recall that ∣A∣ decreases
monotonically throughtout the algorithm). Or, in other words, at the start of the i-th iteration
with currently available vertices Ai and higher-degree vertices Xi scheduled for removal,
∣Ai′∣:=∣Ai∖Xi∣>R.
Using the bound (2) on the edge-count:
eG(Ai′)≥β(2∣Ai′∣)=β2∣Ai′∣(∣Ai′∣−1)
As we choose vti with maximum degree from Ai′, we know vti must at least have the
average degree (4) of Ai′:
We find that the set of available vertices A shrinks at least by a factor of (1−β) in
every iteration. Together with the fact that the initial set A is V(G) we obtain a
contradiction to the initial condition (1) on the number of vertices in G:
∣A∣≤(1−β)qN≤e−βqN≤R(5)
Here we used the well-known inequality (1+x)≤ex. After q iterations, the initial set
of available vertices has necessarily shrunk to a set of at most R vertices.
Final bound
Let us now finally give the bound on the number of independent sets of size exactly q+k.
The bound (3) follows from the observation, that there are at most (qN) different ways
to choose S and therefore the first q vertices of an independent set, and at most
(kR) different ways to choose the k remaining vertices from A, which has size at
most R.
Another useful, but less sharp bounds, can be obtained from one of the various inequalities on
the binomial coefficient:
∣I(G,q+k)∣≤q!Nq(kR)(6)
Wikipedia
has an extensive collection of such bounds.
Overview of notation
Vertex set V(G)
Edge count eG(X): Number of edges in G on vertex set X
Neighborhood N(v): set of vertices adjacent to v
Induced subgraph G[A]: Obtained from G by keeping all vertices in A and their edges among them
Independence number α(G): Size of largest independent set in G
Independent sets I(G): Collection of all independent sets in G
Independent sets I(G,m): Collection of all independent sets in G of size exactly m
Further reading
Some ressources for further details, including applications to various combinatorial problems
and extensions of the container method to hypergraphs, are given below:
]]>Meta Blog: Advanced2021-03-31T00:00:00Zhttps://www.umcconnell.net/posts/2021-03-31-meta-blog-advanced/Part 1 of this series went through the
basic setup and customization of this blog for your own purposes. In this part,
I will go through a few technical details, tips and additional notes, that can
allow you to extend the site and troubleshoot errors. This part can also serve
as a project reference or documentation of some sort.
Overview
Before we go into detail about different aspects of the website, here’s a quick
overview of all the different folders and what they contain:
.
├── config Configuration for plugins (e.g. markdown-it, KaTeX)
├── src
│ ├── assets Website assets
│ │ ├── fonts
│ │ ├── icons
│ │ ├── images
│ │ │ ├── favicon Icons and images for Web App
│ │ │ └── posts Images in posts
│ │ ├── other Other assets (e.g. PGP key)
│ │ ├── scripts JavaScript
│ │ │ └── modules
│ │ └── styles
│ │ ├── base Base styles (e.g. markdown, CSS reset)
│ │ ├── components Styling for various components
│ │ └── utils CSS utilities
│ ├── components Nunjucks components (e.g. card, tags)
│ ├── data Website metadata
│ ├── includes Nunjucks includes (e.g. footer, navbar)
│ ├── layouts Nunjucks page layouts (e.g. base, post)
│ ├── pages Concrete pages (e.g. about, post archive)
│ └── posts Markdown posts
└── utils JS utilities (e.g. filters, shortcodes)
Styling
Styling is done using SCSS. All stylesheets are
located in
src/assets/styles.
The styles are then imported and bundled in main.scss.
The styles are grouped into three main folders:
base:
The base styling comprises basic stylesheets used globally throughout the
page, such as normalization or typography. These styles are very generic,
meaning you probably want to modify styles in different places, such as the
components/ folder for specific components.
components:
These styles consist of more specific styles tailored to certain components,
such as the footer, the navigation or the post tags. This is probably the
best place to modify or add new styles when customizing the website.
utils:
The utilities are mostly SCSS-specific functions, that make use of SCSS’s
scripting features. This is also where the global variables for colors,
breakpoints, etc. are defined for the entire page.
The compilation process, including minification, and error handling is defined
in the
styles.11ty.js
file. In practice, you shouldn’t need to modify this file.
Theming
The blog supports adaptive light and dark themes out of the box (based on the
prefers-color-scheme
media query). The different color palettes are defined in
_variables.scss
under the $themes key.
Individual properties are themed using the t SCSS
mixin. This is for example
how links are themed throughout the blog:
SCSS
a {@includet(color,'link-color');text-decoration: underline;}
The mixin takes a CSS property as the first argument, followed by a variable
name referencing the desired color. This name refers to a field from the
$themes map, which means you can only refer to colors defined as part of a
theme. The mixin takes additional optional arguments, which you can find in the
mixin’s source.
Breakpoints
Breakpoints are also quickly defined using SCSS mixins. There are two mixins,
mq and mq-down, which provide breakpoints starting at, and going up to, a
certain width.
The mixins take the name of a breakpoint, as defined in the global variables. An
example use of breakpoints is when styling the navbar. The following declaration
hides the navigation burger menu for large screens (starting at 940px in width)
and up:
SCSS
@includemq(lg){&__toggle {display: none;}// ...}
Markdown
Markdown files are compiled using markdown-it.
The configurations for markdown-it and it’s plugins are located in the
config/ folder.
The styles for Markdown documents, such as posts, are located in
src/assets/styles/base/_markdown.scss.
Note that Markdown documents must be wrapped in an element with class
.markdown for the styles to take effect. You can thus use the Markdown styles
in HTML/Nunjucks files by wrapping sections in such an element.
Plugins
The following markdown-it plugins are used in this blog:
Additionally, two custom plugins, one for the arrow icons after external links,
and one for the anchor links when hovering over headings, are implemented in the
config folder.
Posts
The blog supports several non-standard additions to Markdown, that add
blog-specific functionality to your posts.
Nunjucks expressions
You can write Nunjucks markup directly in your markdown posts, just as you would
in the other pages. Just wrap the expression between two curly braces:
{{ Nunjucks expression }}. For example, you can conveniently link to
the page’s code repository, directly in Markdown, like this:
MD
You can find the source code [here]({{ meta.code.repo }}).
Shortcodes are another very practical feature of Nunjucks in Markdown. All
shortcodes are defined in
utils/shortcodes.js, and you can
add more. Shortcodes expand to a longer parameterized expression.
Standard shortcodes only take arguments, such as in this example:
MD
{% 'icon pencil' %}
This produces an SVG element:
The standard shortcodes available out of the box are:
icon to embed icons from src/assets/icons/
ytvideo to embed YouTube videos based on their id
There are also paired shortcodes, that wrap a markup section, such as this one:
MD
{% msg 'info' %}
An informative message that **even** supports _Markdown_!
{% endmsg %}
This produces the following:
INFO
An informative message that even supports Markdown!
The paired shortcodes available out of the box are:
msg for message boxes
details for an expandable HTML summary/details element
KaTeX
You can also include math expressions in your post. The expressions are compiled
using KaTeX, which allows you to write TeX-like
expressions. All KaTeX configurations are located in
config/markdown-it/katex.js.
For inline math expressions, wrap your code in single dollar signs: $math$.
For example, you can easily include fractions:
MD
A fraction $\frac{a}{b}$ includes a numerator $a$ and a denominator $b$.
This produces the following text:
A fraction ba includes a numerator a and a denominator b.
For blocks of math, wrap your code in double dollar signs: $$ math $$.
For example, you can display Euler’s identity:
MD
Euler's identity:
$$e^{i \pi} = -1$$
This results in:
Euler’s identity:
eiπ=−1
You can find all supported expressions and formatting options in the
KaTeX docs.
Nunjucks
Nunjucks is used as the templating
language for the blog.
There are several places where Nunjucks is used:
src/components/:
Nunjucks allows imports of so-called
macros, which
are used to represent the components. Macros are similar to functions and
accept arguments to construct a parameterized output.
src/includes/:
Nunjucks’
includes allow
you to literally include chunks of markup as reusable units. This is used
for non-variant parts of the website, such as the footer, header, etc…
src/layouts/:
Layouts are page skeletons that are used as a common base among pages.
The base layout is the HTML skeleton for all other pages and layouts.
The post layout extends this base layout to include additional stylesheets
for code highlighting or the utterances comment widget.
src/pages/:
The pages represent concrete pages of the website, such as the
About page or the Projects page. These are written
with Nunjucks, but already include front matter for 11ty.
11ty
Most of the 11ty-related configuration is placed in the
.eleventy.js file.
Note, that if you are serving this website from a subproject on Github pages,
i.e. when you are not using GH_USERNAME.github.io, but rather
GH_USERNAME.github.io/PROJECT/, you must change the 11ty pathPrefix field in
the configuration file. The setting is commented out in this website’s
configuration.
In development mode (npm run dev), Markdown posts and images in the
src/posts/drafts/ folder will also be built and served. They do, however, not
appear in production mode and are not tracked by git.
Icons
All icons placed in the
src/assets/icons/ folder will be
grouped into an SVG sprite to improve loading time. The icons can then be used
via the iconshortcode.
You can find the full list of available plugins in the
11ty docs
Webpack & Babel
All JavaScript code referenced in
src/assets/scripts/main.js
is transpiled to backwards compatible JavaScript using
babel to support older browsers.
The code files are then bundled using webpack, with
the webpack configuration file located at
src/assets/scripts/scripts.11ty.js.
The bundling process uses an in-memory file system to bundle the scripts in
memory and return the bundled result as a reusable JS string.
Github
The site is automatically built and linted using the provided Github Actions
workflows. The workflow files are located in the
.github/workflows/ folder.
The lint action uses Prettier to check the code for styling and formatting
issues. See the VSCode section for information on the Prettier
extension to automatically format your code when you save.
VSCode
For VSCode users, I recommend installing the
Prettier extension
to automatically format your code and posts on save. All recommended
plugins are listed in the .vscode/ folder.
These recommendations should be automatically suggested when first opening the
project in the editor.
That was it. Thanks for reading!
]]>Meta Blog: Basics2021-03-30T00:00:00Zhttps://www.umcconnell.net/posts/2021-03-30-meta-blog-basics/In my Hello Internet post I announced my
intention to write a post on how I set up this blog and how you can do the same.
The time has now finally come, and the original idea has morphed into a two-part
series. Enjoy!
INFO
This tutorial is primarily meant for beginners. It explains cloning this blog
from Github, personalizing it with custom icons, name and color, and finally
publishing it with Github pages. Part 2
goes further into the technical details of the blog.
If you prefer getting started right away, feel free to skip to the
Getting started section. Also, there is a
video tutorial available for a visual guide on the setup
process.
Static Site
Before we dive into building a static website, it is helpful to quickly look at
what a static website actually is.
On Wikipedia, a static website
is defined as “[…] a web page that is delivered to the user’s web browser
exactly as stored, in contrast to dynamic web pages […]”. Concretely, this
means no dynamic pages, no fancy PHP scripts and no on-page user login. Only
plain good ol’ HTML, with some additional CSS and JavaScript Why would one want
such a boring thing?
Well, it turns out there’re quite a lot of advantages to static sites, if all
you have is static content. Static sites are…
faster: only HTML, CSS, JS and images are served
safer: no login systems, etc. means a minimal attack surface
more accessible: an old browser and a slow internet connection is fine
cheaper: free hosting available, e.g. with Github Pages or Netlify
… than their dynamic counterparts.
A static site doesn’t necessarily mean being limited in functionality, or having
a site consisting of only text and images. There are a lot of possibilities on
the front-end, ranging from embedded YouTube videos and RSS feeds to a
comment system (more on this later on and in Part 2).
SSGs
When creating your static blog, it can be helpful to use a Static Site Generator
(SSG). An SSG helps to make the development and editing process comfortable.
Instead of writing your posts in plain HTML, you can write them in Markdown and
have the SSG convert your posts to HTML files.
This is a similar idea to the concept of compiling code from a higher level
language (such as C or Rust) to machine code, allowing you to write fast code
in a simpler and human-readable form. The process of “compiling” your website
will be referred to as building in the following.
In this guide we’ll be talking about setting up and configuring an SSG called
11ty (pronounced eleventy). 11ty runs on top of
Node, which allows you to benefit from the massive
JavaScript ecosystem and write your own plugins in JavaScript.
Getting started
Prerequisites
Before we get started with the setup, make sure you have the following
prerequisites:
git: You can find installation instructions for all platforms
here
The package.json file describes your node project. It mainly contains
information about the project’s source code and package dependencies.
You can add your name to the author field and change the description field
to your liking.
The name and repository.url fields should contain your project name and
source code repository. The project name should be GH_USERNAME.github.io, the
repository url http://github.com/GH_USERNAME/GH_USERNAME.github.io
accordingly. Replace GH_USERNAME with your Github username.
LICENSE
Modify the LICENSE file to mention your name as the Copyright owner in the
first line.
src/site.webmanifest
The src/site.webmanifest file describes the web app behavior of your blog.
This controls how the website will be presented when a user adds the blog to
their home screen, i.e. installing the web app.
Here, you can change the name and short_name field.
src/data/meta.json
Finally, the last file to personalize is src/data/meta.json. This file
contains important meta-information about the blog, such as the author, the
source and comment repositories for the blog, etc.
Make sure to change the title and author fields, which will for example
change the footer or the about page of the blog.
The url should contain the final URL of the website, i.e.
GH_USERNAME.github.io, where GH_USERNAME is your Github username.
Custom domain
If you do not want to use a custom domain name for your website, such as
example.com, set the custom_domain field to false.
If you own a domain and want to set it up for your blog, you can specify your
custom domain in this field. This then generates a CNAME file in the build
output for you to configure with Github pages. See
this article
in the Github docs on for instructions on how to set up a custom domain for your
site.
Most importantly however, change the fields in the code section of the
webmanifest:
The repo entry should point to the Github repository of the
website (https://github.com/GH_USERNAME/GH_USERNAME.github.io).
The comments field points to the repository that will save user comments
from the blog. This should be GH_USERNAME/comments. We’ll create this repo
later.
Once you’ve saved the files, you should be able to see your name appear on the
blog.
Icons
To change the icons that appear in the header, when installing the web app,
etc., navigate to src/assets/images/.
The avatar, displayed in the header of the website, can be changed by replacing
the avatar.png file with your own image. You may also change the email.png
image, which is displayed in the about page as your contact information.
The icons used for the web app are located in the favicon/ subfolder. When
replacing these icons with your own, custom icons, make sure to keep the naming
and size of the individual files.
Colors
If you want, you can further personalize the blog with custom colors, styles,
and more. All styles and related configurations are located in the
src/assets/styles/ folder. Stylesheets are written in
SCSS. Note that all valid CSS is valid SCSS, which
means you can style the blog in plain CSS if that is more familiar to you.
More specifically, the colors used throughout the web page can be changed in the
utils/_variables.scss file. The main theme color is defined by the
$brand-color-primary variable.These variables are used in all the other
styles, which means it should be enough to change the colors in this file.
Comments
The last thing to do personalize your new blog is to activate the comments
functionality. The blog uses a free service called
utterances, which takes care of managing your comments.
It will display a widget at the bottom of your blog post, that lets users leave
a comment. Note that the comments widget is not displayed when you are in
development mode and serving your blog on localhost (npm run dev). It will
appear in the online version.
The comments are stored in a Github repository, which means you don’t need to
worry about storing your comments. To be able to store comments in a Github
repository on your behalf, you will need to install the the
utterances Github app. Follow the link and
click the install button. You will need to grant the app access to your
repositories. You can later restrict access to the comments repo only in your
settings.
First post
Your new blog should probably contain a introductory post. All posts are written
in Markdown and located in src/posts/.
Go ahead and delete the posts already in the folder (all files ending with
.md). Next, create a file called YYYY-MM-DD-hello-world.md, where YYYY,
MM and DD refers to the current date (e.g. 2021-03-14).
You place the following text into the file and modify it to your liking.
Changes you make to the file should be reflected instantaneously in your web
browser.
MD
---title: Hello World
date: 2021-03-14
description: >
Hello World introductory post.
tags:
- hello
- world
- intro---
Hi everyone!
This is my _brand new_ blog. **Enjoy**!
That’s it! You’re blog is ready to go online.
Publishing
After customizing the blog, we are now ready to publish our blog. We will
publish the blog on Github pages. After following
these steps, your page will be available at https://GH_USERNAME.github.io.
Committing
Start by committing all your customization changes to git. In the root folder
of the blog, run:
BASH
gitadd.git commit -av
Creating Repositories
Next, we’ll create the Git repositories that will hold the source code of your
blog and the comments to your posts.
In your web browser, navigate to github.com/new to
create a new repository.
For the comments repo, enter comments as the repository name. Make sure, the
repo visibility is set to “Public”, before hitting the “Create repository”
button.
Repeat this step for the repo that is going to hold the blog’s source code.
Enter GH_USERNAME.github.io as repo name (where GH_USERNAME is your Github
username) and select the visibility “Public”. Then, create the repository.
You should see a set of instructions to publish your code. Note the instructions
to “push an existing repository from the command line”. When executing these
instructions in the root folder of your blog, you will need to change one
command. Because you have cloned the original blog code from Github, it already
has a remote git origin set. You will need to use set-url instead of add
here:
BASH
git remote set-url origin https://github.com/GH_USERNAME/GH_USERNAME.github.io.git
git branch -M main
git push -u origin main
Github Pages
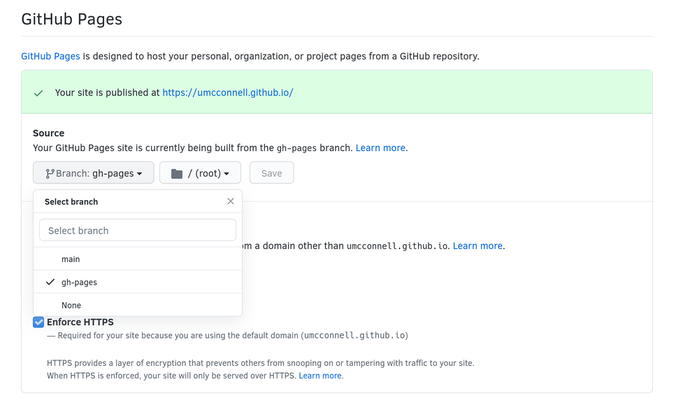
The last step is to publish your pages using Github pages. In your repository
containing the blog source, navigate to the “Settings” tab. Almost at the
bottom of the page, you should find a “Github pages section”.
From the source drop-down, select the “gh-pages” branch. After hitting the save
button, your site should be available online.
Video tutorial
My friend Boldizsar Zopcsak and I recorded a video tutorial about this whole
procedure a little while ago. The video goes through the basics of cloning,
personalizing and publishing your next blog. Feel free to have a look:
For a look at the technical details of this blog, head over to
Part 2 of this series.
]]>Fibonacci in Rust2021-03-13T00:00:00Zhttps://www.umcconnell.net/posts/2021-03-13-fibonacci-rust/You’ve probably already heard of the Fibonacci sequence. It is a sequence of
numbers named after the mathematician
Leonardo of Pisa, that’s generated
using a simple rule, yet pops up in many unexpected places in math and nature,
often in relation to the golden ratio.
To generate the sequence, start with the sequence 1, 1. Then, generate the
next element in the sequence by adding up the last two elements:
1, 1
1, 1, 2
1, 1, 2, 3
…
Mathematically, this can elegantly be expressed using recursion. In this
formula, n represents a given position in the sequence starting with 0.
fib(n)={1fib(n−2)+fib(n−1)if n≤1if n>1
Implementation
We will be implementing the Fibonacci logic using Rust. Rust is a programming
language initially developed at Mozilla that can guarantee memory safety, while
at the same time being super fast. We’ll try out different approaches and see
which one runs fastest.
If you want to follow along on your computer, you can find simple installation
instructions for Rust and cargo, the Rust package manager, for just about any
OS, on the Rust homepage:
https://www.rust-lang.org/tools/install.
Alternatively, you can also code along online on the
Rust playground without having to install
anything!
Setup
If you are not coding along on your machine, feel free to skip this section.
First, let’s create a new Rust library project from the command-line using
cargo:
BASH
cargo new --lib rust_fibonacci
cd rust_fibonacci/
The file src/lib.rs is where we’ll be writing source code later on. You can
delete it’s pregenerated contents for now, as we won’t go through writing tests
for such a simple program.
Now, the only aspect missing is the benchmarking, so that we can compare the
different approaches to calculating the Fibonacci sequence. To do this, we can
use the criterion crate, which allows
us to write benchmarks and run them using cargo. Add the following code to the
Cargo.toml file, just below the [dependencies] section at the bottom:
If you're using the Rust playground, just add all the code examples above the
`main` function. The playground just allows you to use one single file to write
your code in.
Now, let’s get coding! Probably the most straightforward way to implement the
Fibonacci sequence, would be to just start with two variables a and b, that
keep track of the last two elements of the sequence and build from there. Let’s
do that! Add this code to src/lib.rs:
RUST
pubfnfib_standard(n:usize)->usize{letmut a =1;letmut b =1;for _ in1..n {let old = a;
a = b;
b += old;}
b
}
Notice the pub keyword: We use it, so that we can import the code from other
files. This will be useful when benchmarking the functions later on.
Here, we declare a and b as mut, i.e. mutable, to allow us to mutate
or change their values. In Rust, all variables are imutable by default.
We start our loop at 1, because the first two values are already defined and
the range is non-inclusive for its end.
#2: Recursion
Another approach to implementing the Fibonacci algorithm would be to just
translate the recursive mathematical definition from the introduction into Rust
code. Add the following function in src/lib.rs:
RUST
pubfnfib_recursive(n:usize)->usize{match n {0|1=>1,
_ =>fib_recursive(n-2)+fib_recursive(n-1),}}
In this case, the match operator comes in really handy. It works just like the
conditional function definition in math! It is short, clean and concise. This
means we don’t have to write endless if { ... } else if { ... } else { ... }
clauses.
One last thing to note, is the implicit return. We did not have to use the
return statement, because the last expression is automatically returned.
However, it is important not to end with a semi-colon, which would make the
function return nothing (or (), to be more precise).
When we take a close look at this function, it might become clear that it is
pretty inefficient. When calculating fib_recursive(n), we end up calculating
the Fibonacci sequence twice every step down from n, although
it would be enough to calculate the sequence once. This is where
memoization comes in.
Runtime complexity
The recursive approach has the runtime complexity O(2n).
This is because the time complexity of fib_recursive(n)approximately doubles for every n, because it computes fib_recursive(n-1)
and fib_recursive(n-2).
If we want to be more exact about the statement “it approximately doubles”, we
can say the following about this factor a:
ana2a=a(n−1)=a=21±5++a(n−2)∣:a(n−2)1
We can safely ignore the second solution 21−5, which is
negative. This leaves us with a=21+5, the
golden ratio. What a coincidence!
The asymptotically tight bound on the running time of fib_recursive is thus
Θ(an), where a is the golden ratio.
You can find out more about asymptotic notation in computer science on
Khan Academy.
#3: Memoization
We will use a
std::collections::HashMap,
which is similar to a dict in Python or an Object in JavaScript,
to keep track of all the values we’ve already calculated. Then, we can quickly
check, whether a given value has already been encountered and can return this,
before wasting time on a redundant calculation. Add this code to your lib.rs
file:
RUST
usestd::collections::HashMap;pubfnfib_memoization(n:usize, memo:&mutHashMap<usize,usize>)->usize{ifletSome(v)= memo.get(&n){return*v;}let v =match n {0|1=>1,
_ =>fib_memoization(n-2, memo)+fib_memoization(n-1, memo),};
memo.insert(n, v);
v
}
We first check, whether the current n is in the HashMap, by checking whether
the value at n is Some. If no value has jet been recorded, memo.get(&n)
will return None and the pattern won’t match.
Next, we compute the sequence value just as when using plain recursion. The only
difference is, that we save the value to our memo before returning it.
Notice how we write &mut HashMap<usize, usize> in the function definition.
This is part of Rust’s borrow checker, that ensure memory safety for our
program. By declaring the memo as mutable, Rust ensures that only one part of
the program has write access at a time and that no other part of the program can
read from the memo while we have write access to it and might be modifying it
unexpectedly.
#4: Iterator
One last way to implement the Fibonacci sequence that this post will cover is
using Rust iterators. You might be familiar with this concept, especially if
you’ve already used
Generators in JavaScript
or Iterators in Python.
Rust iterators implement the
Iterator trait and
expose a next function, which returns the next element of the iterator or
None, if the iteration is over.
Lets implement this iterator principle using a struct. The struct will save
the last two elements a and b of the sequence, starting at 1. It will
then generate the next value just as in the standard approach:
A few things to notice here. First, notice how we all methods of the struct are
wrapped in impl blocks. This separates the struct definition from it’s
methods, helping your code stay clean.
Also, we write a default method that takes no arguments and returns an
initialized FibIterator. As this method is not associated to a struct
instance, i.e. an initialized FibIterator with concrete values for a and
b, it is called an associated function. We can call these types of functions
using ::. In this case, we would call FibIterator::default() to construct a
new instance.
The Iterator and Default traits are implemented using the impl Foo for Bar
statement. In the impl block of the Iterator trait, we define a next
function that just returns the sum of the two last elements in the sequence.
This way, the iterator can just keep generating new integers of the sequence
on demand. Because iterators in Rust are lazy, these integers are only
generated when needed.
INFO
A trait is a set of common functions all structs must implement, to have this
trait. In the case of Iterator, this is solely the next function.
Traits are useful, because they allow other functions to accept different types,
while making sure that all of these different types share a common interface.
When implementing Iterator, this trait unlocks a whole set of other useful
methods such as skip, take, filter, and many more, that all rely on the
next method we implemented. These all come built-in with the trait and we
don’t need any additional work to implement these.
Iterators are an important part of Rust, as they allow to write code in a
concise functional style, while incurring no additional performance. When
compiling the code, Rust will optimize the operations away and turn the
iterators into classical for loops in the background. That means you don’t have
to choose between writing fast and clean code, you can do both!
Bechmarking
Finally, we will compare the different approaches by benchmarking the different
functions. Add the following code to the benches/fibonacci_benchmark.rs file.
Note that benchmarking does not seem possible on the online Rust playground.
This code creates a test group called Fibonacci and benchmarks the four
different approaches using the same input. Run the benchmark in your terminal:
BASH
cargo bench
Once the benchmarks are done, you can view a nice HTML report in your browser by
opening target/criterion/Fibonacci/report/index.html. Running on my machine
gave me the following stats:
You can clearly see, that the naive recursive solution is the least performant
approach, as its execution time increases (exponentially, but not visible with
2 inputs) with the workload. The memoized version, in contrast, shows a great
improvement, but it still incurs the performance overhead of initializing and
managing the memo, making it less performant than the two last approaches.
The iterator and standard seem to be indistinguishable. On my machine, the
execution of the iterator takes ~34ns for both inputs, the standard approach
around ~4.5ns for both inputs.
You can find more detailed graphs and charts for every function in the
corresponding target/criterion/Fibonacci/<APPROACH>/report/index.html folder.
Conclusion
We’ve implemented and benchmarked four different approaches to generating the
Fibonacci sequence.
Although the recursive solution is short and concise, it is by far the least
performant and can become too slow to calculate for larger inputs. The memoized
solution is interesting, in that it combines the conciseness of the recursive
approach with a greater speed. The standard approach, on the other hand, seems
to be the fastest, but it is arguably the least elegant.
Finally, the iterator solution appears to be by far the most versatile while at
the same time being very fast. Additionally, it allows the user to work with the
sequence in a very convenient way, e.g. by filtering, mapping, etc.
Overall, it becomes clear that iterators are a very versatile and performant
aspect of Rust, that are also worth considering in other languages such as
Python or JavaScript.
This is the first post on my new blog, and I’m really excited. I hope to write
more in the coming weeks and months, especially about technical and
software-related topics. My goal is to write about current software side
projects and things I’ve learned, all in the spirit of
“Stay curious, keep learning”. Depending on how that works out, I’ll adapt if
needed.
Outlook
A few topics I’d like to cover soon are AI, Rust and how I set up this blog, to
give some ideas in case you would like to do the same. In the meantime, as this
blog is entirely open source, I invite you to check out the
source code on Github,
fork it, make it your own, or whatever you want.
Why?!?
I hope to learn something useful from this experience and gain some more
experience building websites. Writing down ideas and summarizing problems is a
good exercise, all while improving writing skills. A blog also let’s me document
findings and ideas for later use or for someone else to be inspired.
And maybe I can even help solve a problem on the way or motivate to learn
something new!
Feel free to comment on any post, give feedback, suggest improvements, correct
me or whatever else you think is appropriate.
 Case
Case